
The PAWDOC collection was set up in 1981 to explore the application of office technology. In 2001 a paper was published in the Journal Behaviour & Information Technology called ’20 years in the life of a long term empirical personal electronic filing study’. This described PAWDOC and summarised findings about its use up to that point under the following 15 headings:
- Collection content, size, growth rate and usage patterns (this post)
- Deciding what to file
- Indexing
- Scanning
- Searching
- Use of information
- Archiving
- Hardcopy/electronic mix
- Relationship between work patterns and filing activities
- Technology requirements and problems
- Portability
- Sharing files
- Confidentiality, ownership and intellectual property rights
- Reliability and Longevity
- Costs and benefits
Two extra considerations are ‘Architecture‘ and ‘Requirements and Objectives‘. Now, a further 18 years on, the findings will be further reviewed in this and subsequent posts. The first of these follows below.
Collection content, size, growth rate and usage patterns
The precursor to PAWDOC was a conventional filing system in an upright cabinet using hanging folders and crystal tabs to store documents only (not journals, books etc.). The contents were specified in an index taxonomy with entries of the type, for example, 1.6.8 – Quarterly Progress Reports, which I was constantly adding to. Consequently much space was taken up in the cabinet by folders with crystal tabs housing only a few pages. This changed after the PAWDOC system came into use: it needed far fewer hanging folders because each folder was filled to capacity with as many of the serially numbered documents that it could take.
The PAWDOC schema was explicitly defined to support the management of multiple sets of different material owned by multiple different owners. This capability was used to manage a variety of sets of my own material in addition to documents, for example, several different journals, 35mm slides (for making presentations), ring binders, and books; and, in the early years of the system, material owned by other people and organisations – though, as time went by, I made fewer and fewer such entries not least because of the uncertainty of being able to access such material.
The system soon became an integral part of my working life, and I used it just about every day. Several hundred new items were being added each year and this steady rate of acquisition soon ran up against the physical limits of the upright cabinet, so it became necessary to archive material in boxes and then to put some of the boxes in store. This went on until I started digitising newly acquired documents in 1996 and disposing of most originals. At this point, I also started to store born digital documents regardless of the applications they were created in.
In 2001 I started a new job in Bid Management which precluded personal storage of its associated highly confidential and fast moving documentation; so my useage of the PAWDOC system did reduce from then onwards. Nevertheless I continued to use it regularly on most days, and was still adding over 200 new items each year up to when I retired in 2012.
The 45 boxes of hardcopy that I had acquired eventually came out of store around 2001 and were stored in my garden shed. Their number was overwhelming and I began to doubt I would ever get them all digitised. However I stuck at the task, sometimes going at it solidly for several days at a time when my wife was away. By the time I retired in 2012 only 4 boxes remained and these had all been scanned by 2014: it was a great relief. The huge amount of physical space taken up by the collection had been reduced to just two archive boxes of significant hardcopy documents; and, after I had conducted a digital preservation exercise on the collection in 2018, the digital footprint of the collection amounted to some 115Gb. I have ended up with a fairly complete digitised archive of all the non-highly confidential materials that I had encountered throughout my working life, including substantial amounts of material from my earlier career from 1972 with Kodak and then CPC. Since retiring I’m continuing to add a few documents (around 40 up to 2019) in three categories: significant articles relating to the work I used to do; documents relating to the digital preservation of the PAWDOC collection; and material relating to work I am doing to investigate and document the findings from the PAWDOC collection’s 38 years of existence.
Specific questions relating to this aspect are answered below. Note that the status of each answer will fall into one of the following 5 categories: Not Started, Ideas Formed, Experience Gained, Partially Answered, Fully Answered.
Q1. What are the contents of the collection?
2001 Answer: Fully answered: At the beginning of July 2001, the collection consisted of 14,100 index entries representing approximately 185,000 pages of paper, 50,000 scanned pages, over 30 scientific journals (including Behaviour & Information Technology from 1982), around 30 books and conference proceedings, 3700 MS Word files, 400 MS Excel files, 250 MS PowerPoint files, 150 other electronic files of various types, and 10 CDs.
2019 Answer: Fully answered: The PAWDOC user Guide created in 2018 says: “All types of documents were stored including letters, internal memos, circulars, reports, specifications, minutes, overhead slides, 35mm slides, notes, training materials, brochures, manuals, maps, emails, computer magazines, journal articles, conference proceedings, and videos. As Office Technology became more versatile, electronic documents such as word processor files, spreadsheets, presentations and web sites were also filed.”. In June 2019, the collection consisted of 17,293 Index entries representing 29,610 electronic files in 16,067 Windows folders, and about 340 physical hardcopy documents in two archive boxes. A further 384 old electronic backup files are also stored in a separate folder. The The checking exercise conducted in 2016 identified the following numbers of different types of files in the collection: Word – 6380; Powerpoint – 466; Excel – 625; HTML – 382; Help – 90; Zip – 92; 11 other apps – 88; Scanned documents – 28,418. The collection was primarily a work collection and therefore the number of new items being included reduced to a trickle when I retired in 2012.
Q2. How much space does the collection take up?
2001 Answer: Fully answered: The paper takes up about 4.7 sq. metres of floor space and 1.7 metres of shelf space. The scanned images and electronic files take up 2.9 GB. The scanner, magneto-optical drive and CD Writer take up about 0.25 sq metres of desk space. The Filemaker Pro index is about 8.1 MB in size and the FISH data file is 11.2 MB. The Filemaker Pro, FISH, SQL Anywhere and Easy CD Creator software packages take up approximately 38 Mb.
2019 Answer: Fully answered: The two archive boxes stand one upon the other and take up 0.2 sq m of floor space. The laptop in which the electronic files reside takes up 0.08 sq m of desk space. The electronic files of the main collection take up 45.9 Gb storage space; and the backup files take up 66.6 Gb. The Filemaker Pro software used for the index takes up 336 Mb of file space.
Q3. What is the growth rate of the collection?
2001 Answer: Partially answered: Between 1981 and 1993 an average of 543 index entries were created each year – estimated to consist of an average 29.4 pages per day (Chan 1993:25).Over the whole 20 years life of the system, the growth rate has been an average of 705 entries per year with a range of 210 ± 1202new entries a year. In 1993, it was estimated that the collection was increasing at the rate of 3.8 MB per day.
2019 Answer: Fully answered: The growth rate of the collection is shown in the chart below.
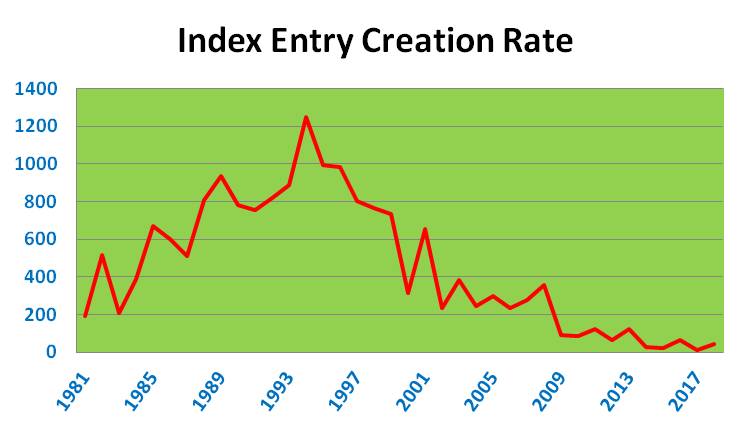 There are three distinct phases: 1981 – 2000; 2001 – 2011 when I was working on highly confidential bids; and 2012 – 2019 when I was retired. The average growth rates per year during these periods were:
There are three distinct phases: 1981 – 2000; 2001 – 2011 when I was working on highly confidential bids; and 2012 – 2019 when I was retired. The average growth rates per year during these periods were:
- 1981-2000 – 696
- 2001-2011 – 272
- 2012-2019 – 46
Q4. How often are the contents accessed?
2001 Answer: Experience gained: Between 1987 and 1993, an average of 363 records were being accessed each year (Chan 1993: 25)
2019 Answer: Experience gained: The only data that has been collected on this question is in the date last accessed field, and unfortunately that only records the latest date an item was accessed – there may have been any number of earlier accesses. Furthermore, some items may have been accessed without the date last accessed field being updated. Having said that, 4,551 items have an entry in the date last accessed field, implying that 12,742 items have never been looked at for work purposes after they had been included in the collection (the date last accessed field was never updated when items were looked at for the purposes of controlling and writing about the collection). For the period from 2001 onwards, when I moved jobs into Bid Management, there were 751 index items with dates of 2001 or later in the date last accessed field (only 15 of these were in 2012 and only a further 15 of these were from 2013 onwards).
NB. The various references in the texts above to Chan,1993 relate to the following reference at the end of the 2001 paper in Behaviour & Information Technology:
CHAN, S. C. 1993, Feasibility of Paperless Office, Submitted in partial fulfilment of the requirement for the degree of MSc in Information Systems and Technology in The Information Science Department at City University, London (Supervisor: Dr David Bawden) [PAW/DOC/4012/08].