This entry has been jointly authored by Paul Wilson and Peter Tolmie
The PAWDOC filing system was set up in 1981 to try and understand how the newly emerging office technologies of that era might assist individuals to manage their office documents. Over its 35+ years of operation much has been learnt, and it is our intention to try and understand and describe those findings. However, the system was set up to address requirements in the office of the 1980s, and there has been a revolution in the way business operates since then. In order to be able to relate the findings to office work today and in the future, this entry explores the differences in requirements for personal filing in the office between the early 1980s and 2019.
Perhaps the most significant difference is the transfer of huge amounts of information from paper-based documents to digital files. Note that this is not saying anything about the current volume of paper in the office (though we would suggest that there is probably less paper filed by individuals now than in the 1980s) – just that individuals now have to deal with huge amounts of electronic material in contrast to the early 1980s when they dealt with virtually none. This transition has been facilitated by a huge growth in the use of computer hardware – desktop computers, laptop computers and mobile phones – throughout the world, from a base of zero to near-universality.
The growth in the use of computers has also prompted huge changes in office work. At the beginning of the 1980s, office professionals used support staff – typing pools, secretaries, and admin support staff – to perform their administrative tasks. However, as office technology became widespread, professionals started to do their own typing and support staff became a luxury which could be cut to reduce budgets. In 2019, only very senior management have secretaries and office workers are expected to be self-sufficient and fully competent in the use of all hardware and software relevant to the realisation of their work.
These changes were accompanied by a revolution in communications. Electronic mail has now almost entirely replaced internal memos and external letters, and has prompted massive increases in the amount and speed of communication. Email also rapidly became the key mechanism for supporting distributed teamwork – nationally and globally – and now underpins a battery of related interests, from the sharing of documents to the organisation of voice conference calls (which are the unsung foundation upon which much of business and government now operates). In more recent years, as mobile phones have permeated throughout the world’s populations, text messaging and chat applications have become an integral element of personal and business relationships. To this highly significant mix of new technologies must be added the recent massive uptake in Social Media. An unfortunate side-effect of the sheer effectiveness and pervasiveness of these mechanisms is high levels of information overload across a large proportion of office workers.
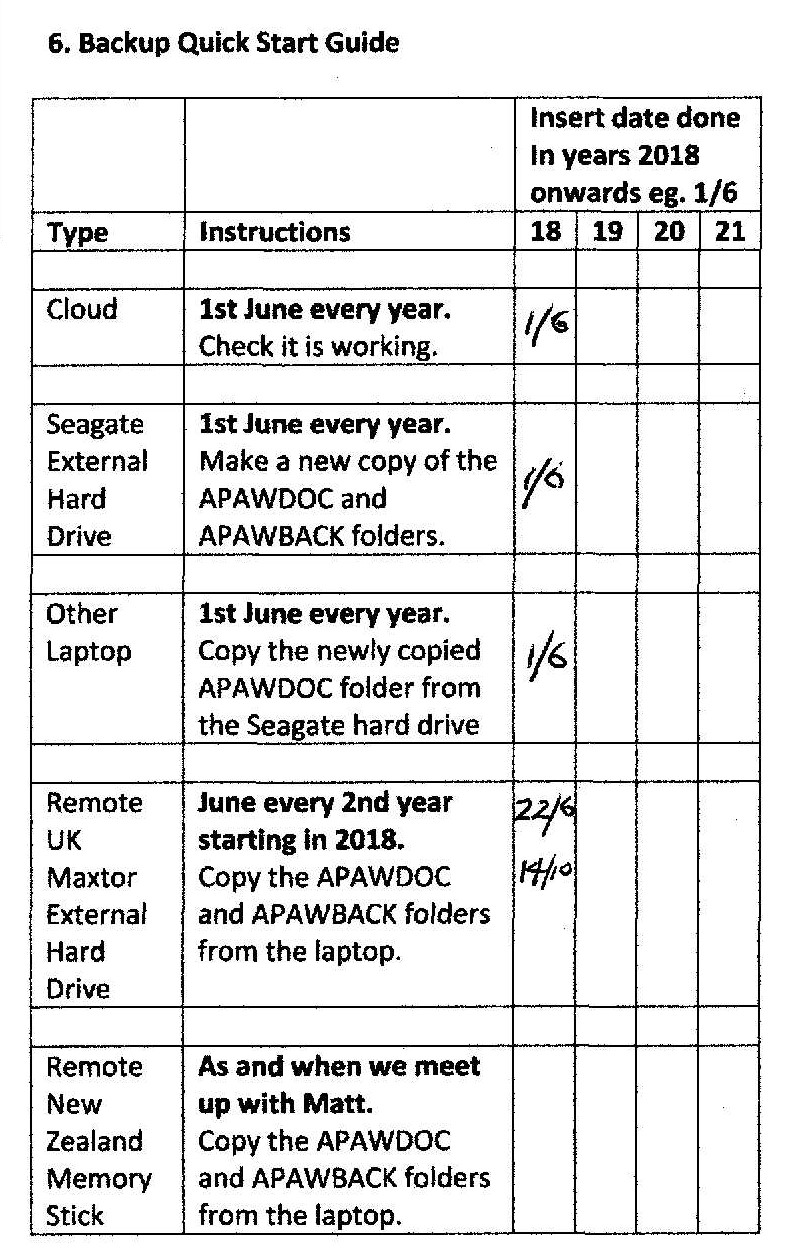
Importantly for the work to derive findings from the long-term operation of the PAWDOC filing system, the changes described above have impacted filing activities in the office. Hot desking and home working have made personal filing cabinets and bookshelves a luxury. The folder systems integral to computer operating systems (primarily from Microsoft and Apple) are now used to store the electronic documents created and received by the individual. At the same time, email systems have their own integral filing systems into which mail can be rapidly sorted and stored indefinitely in the cloud; text messages are stored on users’ mobile phones in the form of text streams by both senders and recipients; and Social Media systems have their own self-contained environments distributed across vast computing networks. The further evolution of cloud-based repositories, such as Dropbox and Google Drive has led to an added utilisation (if not trust) in distributed document stores. Even if users wanted to integrate these different collections, it would be almost impossible for them to do more than just copy selected elements from one to another or to a dedicated filing system: these stores are separate silos and will probably continue to be so for many years to come.
The design of the PAWDOC system in 1981 was based on an understanding of office filing requirements at the time. There was an expectation of how emerging office technology might be used to support those filing requirements, but little appreciation of how the technology itself would change the way business operates. Initially, then, learnings from the development of the PAWDOC system were entirely focused upon what the impact might be of new assumptions about filing built into the construction of computer systems in the early 1980s. Later on, in the middle period of PAWDOC operation, the findings speak to what it was taking to manage a filing system in a changing work environment populated by imperfect but maturing technologies. More recent findings give a somewhat different picture, as many of the troublesome technologies of the middle-era have come to be taken-for-granted resources, giving rise to new kinds of problem, of which information overload is but one potential symptom. What is clear at present is that computer technology and the business world is now changing so rapidly, the presumption present in the early days of PAWDOC – that one could readily identify needs and solutions for the future – now seems somewhat naïve (if still just as pressing).
One thing, however, we believe has remained constant and that is the attitude towards filing across the population. Most people are not motivated to put effort into filing because it is extra work for an indeterminate reward at some undetermined point in the future. A smaller subset of people is willing to put varying degrees of effort into the activity. We believe this has changed little between the early 1980s and the present day. As it happens, the PAWDOC owner was at the more extreme end of this latter group and wanted to file both effectively and comprehensively. Hence the PAWDOC collection contains most of the documents that the owner read and/or believed to be significant in his work; and consequently it should be borne in mind that the learnings derived from his experiences concern almost the worst case requirements of filing load and effort. It should be easier for most of the population. Certainly, it would seem easier, for digital copies are now retained of virtually everything as a matter of course. The extent to which that is oriented to as a personal collection of materials is a different matter, as is the probity of third parties hanging on to everything in that way. These, of course, are burning questions of the moment, and ones to which we shall ourselves return.